
SIGTYP 2020 Shared Task
In 2020, SIGTYP is offering a shared task on the prediction of typological features. The shared task features nearly 2,000 languages, with typological features taken from the World Atlas of Language Structures (WALS).
To participate in the shared task, you will build a system that can predict typological properties of languages, given a handful of observed features. Training examples and development examples will be provided. All submitted systems will be compared on a held-out test set.
You will be invited to describe your system in a system paper for the SIGTYP workshop proceedings. The task organisers will write an overview paper that describes the task and summarises the different approaches taken, and their results.
Important Links
Important Dates
Training data Release: ↣ 26 March 2020
Test data Release: ↣ 20 June 2020 (Released!)
Submissions Due: ↣ 1 July 2020
Writeup Due: ↣ 15 August 2020 22 August 2020 (AoE)
Camera-ready Due: ↣ 10 October 2020
Description
The typological features in WALS represent one approach to the categorization of the languages of the world according to their linguistic properties, e.g. in terms of their syntax, morphology, phonology inter alia. One example of such a typological feature is the basic word order feature. For instance, English is best described as a subject-verb-object (SVO) language whereas Japanese is best described as a subject-object-verb (SOV) language.
One major issue with WALS, however, is that it is both sparse and skewed in terms of language--feature annotations. It is sparse in the sense that most languages only have annotations for a handful of features, and skewed in the sense that a few features have much wider coverage than others. Luckily, such features often correlate with one another, which allows for prediction of those features from others. For instance, languages where the verb precedes the object tend to have prepositions, e.g. Norwegian, whereas languages where the object precedes the verb word tend to have postpositions, e.g. Japanese.
Although there is previous work dealing with versions of this task (Daumé III and Campbell 2017; Bjerva et al. 2019), important facts have been frequently ignored. Some papers control for phylogenetic relationships between languages, e.g. not training and testing on Slavic languages, but little-to-no work has considered controlling for geographical proximity.
Subtasks
The shared task will consist of two settings (subtasks):
1) Constrained: only provided training data can be employed.
2) Unconstrained: training data can be extended with any external source of information (e.g. pre-trained embeddings, texts, etc.)
Data Format
The model will receive the language code, name, latitude, longitude, genus, family, country code, and feature names as inputs and will be required to fill values for those requested features.
Input:
mhi Marathi 19.0 76.0 Indic Indo-European IN order_of_subject,_object,_and_verb=? | number_of_genders=?
jpn Japanese 37.0 140.0 Japanese Japanese JP case_syncretism=? | order_of_adjective_and_noun=?
The expected output is:
mhi Marathi 19.0 76.0 Indic Indo-European IN order_of_subject,_object,_and_verb= SOV | number_of_genders=three
jpn Japanese 37.0 140.0 Japanese Japanese JP case_syncretism=no_case_marking | order_of_adjective_and_noun=demonstrative-Noun
Data
The model will have access to typology features across a set of languages. These features are derived from the WALS database. For the purpose of this shared task, we will provide a subset of languages/features as shown below:
tur Turkish 39.0 35.0 Turkic Altaic TR case_syncretism=no_syncretism | order_of_subject,_object,_and_verb= SOV | number_of_genders=none | definite_articles=no_definite_but_indefinite_article
jpn Japanese 37.0 140.0 Japanese Japanese JP order_of_subject,_object,_and_verb= SOV | prefixing_vs_suffixing_in_inflectional_morphology=strongly_suffixing
Submission
Submissions should be emailed to the SIGTYP email address by end of the day 1 July, anywhere in the world.
Submissions should in the format of the trial data, as shown [here].
Files should be named as {team name}_{unconstrained/constrained} to indicate the subtask.
Description Papers
Papers describing shared task submissions should consist of 4 to 8 pages of content plus additional pages of references, formatted according to the EMNLP 2020 format guidelines. For shared task paper submission, it is not necessary to blind the team name and authors. Accepted papers will be published online in the EMNLP 2020 proceedings and will be virtually presented at the SIGTYP workshop at EMNLP 2020. Writeups should be submitted through softconf [here], and are due by 15 August 2020 11.59 pm [UTC-12h].
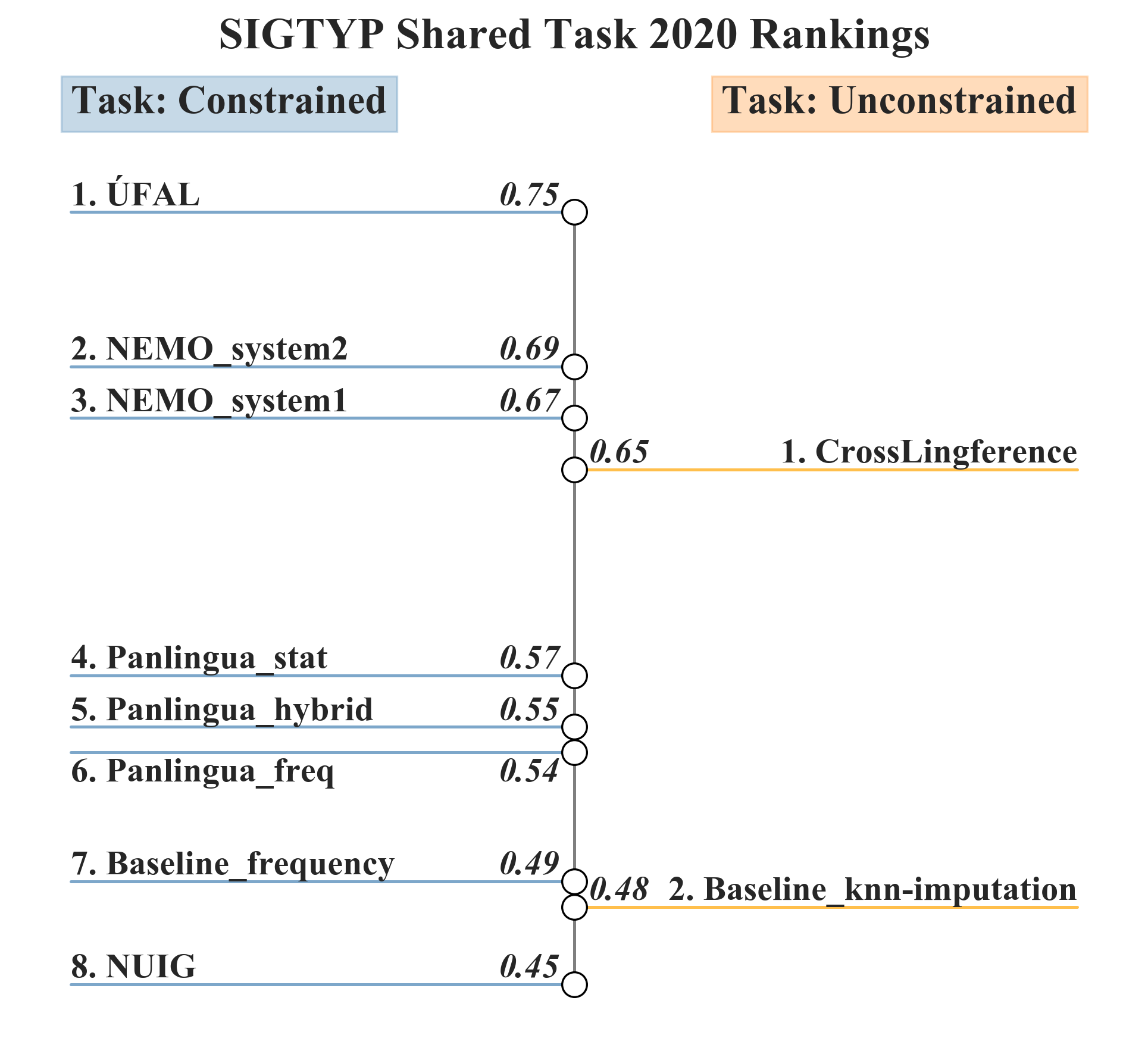
Submission Rankings
Final submission rankings using macro-averaged precision across the controlled genera.
For more detailed analysis with respect to language, family, genus, and feature, please see the forthcoming overview paper and each team's description papers!
Organizers
Johannes Bjerva
Isabelle Augenstein
Aditi Chaudhary
Edoardo M. Ponti
Giuseppe Celano
Liz Salesky
Ryan Cotterell
Michael Regan
Sabrina J. Mielke
Ekaterina Vylomova
Contact
Please contact sigtyp AT gmail DOT com if you have any questions